

Unlocking the Power of Data Lakehouse in Kubernetes: A Comprehensive Guide
Unlocking the power of Delta Lakehouse in Kubernetes is a journey through the realms of data lakes and container orchestration. In this blog post, we’ll explore the seamless integration of Delta Lakehouse into Kubernetes, unraveling the potential it holds for data-driven applications and workflows. Whether you’re a data engineer, developer, or simply curious about the intersection of big data and containerization, fasten your seatbelts as we dive into the fascinating world of Delta Lakehouse in K8S.
Delta Lakehouse, built on top of Apache Spark, brings reliability and performance to data lakes by providing ACID transactions and scalable metadata handling. In the context of Kubernetes (K8S), this technology brings a new dimension to managing and processing large-scale data within containerized environments.
Why Delta Lakehouse in Kubernetes?
Kubernetes, commonly known as K8s, has emerged as the industry standard for container orchestration. It offers a robust platform for deploying, managing, and scaling containerized applications. Its dynamic capabilities make it particularly well-suited for data lakes, allowing organizations to efficiently handle evolving data processing requirements. By harnessing Kubernetes, businesses can take advantage of automatic scaling, fault tolerance, streamlined resource allocation, and simplified deployment of data processing workloads.
Understanding Data Lakehouse
Before diving into the world of data lakehouses in Kubernetes, let’s quickly recap what a data lakehouse is. A data lakehouse is a unified data storage architecture that combines the strengths of data lakes and data warehouses. It provides a single repository for storing structured, semi-structured, and unstructured data, making it ideal for handling diverse data types and formats. Data lakes offer schema enforcement, ACID transactions, and support for both batch and real-time analytics, allowing organizations to run complex queries and perform advanced analytics on large datasets without compromising performance.
Setting Up Delta Lakehouse in Kubernetes
To establish Delta Lakehouse in Kubernetes, utilizing the Spark Operator streamlines the deployment and management of Spark applications interacting with Delta Lake. After installing the Spark Operator, define a SparkApplication custom resource specifying key parameters. Submit your Delta Lake application as a Spark job, prompting the Spark Operator to deploy and manage the Spark cluster dynamically. This automated process includes monitoring the application’s status, adjusting resources based on workload changes, and ensuring optimal efficiency. The integration provides a robust, scalable, and containerized solution for handling significant data processing tasks within Kubernetes. Subsequent sections will delve into specific configurations and practical use cases to maximize the potential of Delta Lakehouse in the Kubernetes environment.
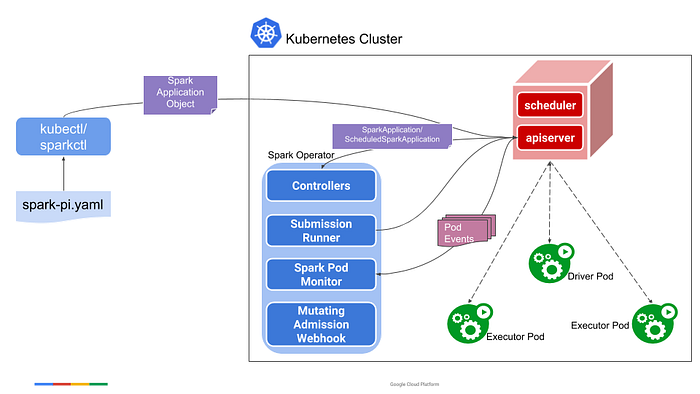
Deploying Spark jobs in K8s
For installing the Spark application in K8s, we use the Spark operator. The Spark operator is a K8s native tool that helps us run Spark applications on K8s clusters. It simplifies the deployment and management of Spark applications by providing a custom resource definition (CRD) that allows you to define Spark applications as Kubernetes resources. we deployed spark application for our project.
A walkthrough for running a Delta Lakehouse Spark application on Kubernetes.
We’re using Delta Lakehouse in Kubernetes, which combines the best parts of a data warehouse and a data lake. Delta Lakehouse can handle both structured and unstructured data. In this blog, we’re trying to set up Delta Lakehouse with the Spark Operator.
Here is a step-by-step guide on setting up a delta lake within a Spark application on Kubernetes.
Version:
- Spark: 3.3.0
- Kubernetes v1.25.6
- spark-on-k8s-operator: sparkoperator.k8s.io/v1beta2
Step 1: Create custom Docker images that include the necessary packages to run a Spark application with Delta Lake support.
Why might you want to create your own special Docker image?
The main reason for creating a custom Docker image, instead of using the default Spark Docker image, is to include additional packages required for executing the code. There were issues with running the packages and dependencies when adding them directly to the deps package in the YAML file. The primary problem that can result in a “ModuleNotFoundError” is the absence of required packages for import.
The packages used for creating Docker images in our project are as follows, but keep in mind that they may vary depending on your specific requirements.
Step 2: Execute the following commands to add a Helm chart repository.
install the chart.
Now the infrastructure is ready. Let’s run the spark job.
Step 3: Create a file as per format you have in mind, over here we are referring to spark-pi.yaml, which is readily available along with spark-on-k8s-operator GitHub, which we have modified for my use case.
To learn more about this file refer to this link.
After executing this command, your application will start running.

For more information, please refer to the GitHub link.
Authorize access to data in Azure Storage
We utilized two different types of Azure storage services for this project.
- Azure Blob storage (Opens in new window or tab)
- Azure Data Lake Storage Gen2 (Opens in new window or tab)
Azure Blob storage
Azure Blob Storage is a cloud-based object storage service provided by Microsoft Azure. It is designed to store and manage large amounts of unstructured data, such as text or binary data, like documents, images, and videos. Azure Blob Storage can be accessed using REST APIs or Azure SDKs, and it can be used to build applications that require scalable and durable storage for unstructured data.
Configuration (Azure Blob storage)
Here are the steps to configure Delta Lake on Azure Blob storage.
- Include hadoop-azure JAR in the classpath.
- Set up credentials.
You can set up your credentials in the Spark configuration property (Opens in new window or tab)."fs.azure.account.key.<storage-account-name>.core.windows.net": "<your-storage-account-access-key>"
Usage (Azure Blob storage)
Data Lake Storage Gen2 converges the capabilities of Azure Data Lake Storage Gen1 with Azure Blob Storage. For example, Data Lake Storage Gen2 provides file system semantics, file-level security, and scale. Because these capabilities are built on Blob storage, you also get low-cost, tiered storage, with high availability/disaster recovery capabilities.
Configuration (ADLS Gen2)
Here are the steps to configure Delta Lake on Azure Data Lake Storage Gen1.
- Include the JAR of the Maven artifact hadoop-azure-datalake in the classpath. See the requirements for version details. In addition, you may also have to include JARs for Maven artifacts hadoop-azure and wildfly-openssl.
- Set up Azure Data Lake Storage Gen2 credentials.
Usage (ADLS Gen2)
Difficulties encountered while running Spark in AKS
- when partitioning the data. Special characters cannot be used in directory names on Azure Storage.
- An open error that prevents the reading of a delta log will occur when foreachbatch in PySpark is being used on Azure.
SparkPodSpec
The SparkPodSpec defines common elements that can be customized for a Spark driver or executor pod. In the following file, we customized the drivers and executors with respect to our resource requirements and computation time.
Conclusion
In conclusion, the strategic choice of Delta Lakehouse in Kubernetes aligns with industry standards, capitalizing on Kubernetes’ automatic scaling, fault tolerance, and resource efficiency. Throughout the setup process, the Spark Operator emerged as a pivotal tool, streamlining the deployment and management of Spark applications interacting with Delta Lake.
In summary, the synergy between Delta Lakehouse and Kubernetes holds immense potential for advancing data-driven applications and workflows. This convergence, at the intersection of big data and containerization, stands poised to shape the future of efficient and scalable data processing.