

You might have heard of ADAS (Advanced driver assistance systems) in many cars nowadays, which are smart enough to detect the human in front of the car and apply brakes automatically. Have you thought what is the technology behind that? Leading car Manufacturers have stepped in to integrate ADAS into their cars. Existing ADAS technologies operate on visual cameras, RADARs, and LiDARs for the object detection. ADAS mainly depends on features such as high speed, high accuracy, low cost, and low power consumption.
In this blog, we will talk about the real-time Object Detection technique YOLO (You Look Only Once). Not only that, I will share how YOLO can help us detect damage in the Car.
What is YOLO?
YOLO or You Look Only Once is a popular Object Detection technique. That means, it performs two tasks Object Classification & Object Localization.Since, there are two tasks many Object detection algorithms such as R-CNN, Fast RCNN, Faster RCNN are using two-step or two neural networks. But as the name itself defines, YOLO — looks at the entire image at once, and only once which allows it to capture the context of detected objects. Due to the single network, it is much faster than other object detection algorithms and can perform real-time detection at 45 frames per second.
There are various versions of YOLO you will find out, the first version was released in 2016, and version 3 which is discussed here was created in 2018. The official successors of YOLOv3 are YOLOv4, and the newly released YOLOv7, which is the current state-of-the-art object detector in 2022.
YOLOv1 Architecture
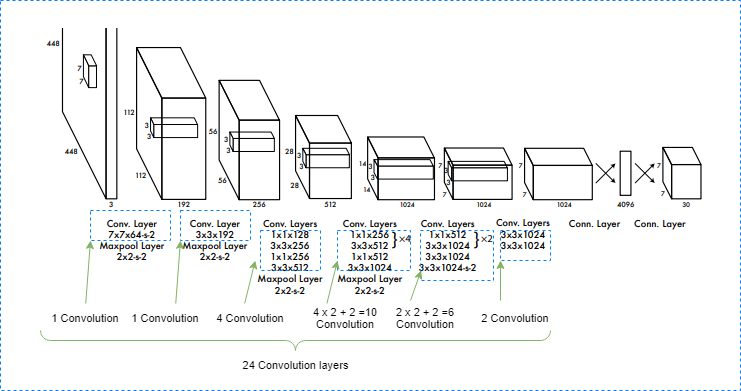
The architecture works as follows:
- Resizing the Input image to 448 x 448 before going through the convolutional network.
- In total, it contains 24 convolutional layers followed by 2 fully connected layers.
- Uses 1×1 convolution layers to reduce the channels, followed by 3×3 convolutional.
- Softmax is used for class predictions.
Difference between YOLOv1 and YOLOv3 Architecture
- YOLOv3 uses 53 Convolutional layers and skip connections.
- YOLOv3 uses logistic regression with binary cross-entropy loss. Since, there is possibility two classes(men & Person) are there for a single box and using softmax imposes that each box has exactly one class which is mostly not the case.
How YOLO works?
Now you have understood the architecture, let’s try to understand how the YOLO algorithm works actually.
“Let’s suppose we have built a YOLO Model to detect the damage in the car.
You will understand the whole process of how YOLO performs object detection; how to get image (B) from image (A)”

YOLO Algorithm works on the following four approaches:
- Residual blocks
- Bonding box regression
- Intersection over Union (IoU)
- Non-Maximum supression
- Residual Blocks
YOLO works on the idea of segmentation of the image into smaller parts. The image is divided into square grid of size SxS like:

The cell in which the center of the object is the cell responsible for detecting that object.
2. Bonding box Regression
The next step is to determine the bonding boxes, each cell can have B bounding boxes. The value of B can be determined while creating model architecture.
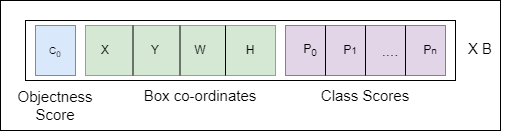
YOLO determines the values of these bonding boxes using a single regression module. Each of the bonding boxes are made up of 5 numbers + N class scores: confidence of box, x position, y position, width, height, and class score. Here confidence score will be between 0.0 and 1.0 with 0.0 means that there is no object in that cell and 1.0 means model is certain there is an object. x and y are the center of the predicted bounding box and width & height are the fractions relative to the image size. Class score are confidence of particular class.
3. Intersection over Union (IoU)
Many times, a single image can have multiple boxes for a single object. IoU helps to find the most relevant box. IoU values lies between 0 and 1. IoU is the area of the Intersection of predicted and ground truth boxes divided by the area of the Union of predicted and ground truth boxes.
- The user can define the threshold value for IoU such as 0.5.
- Thereafter, it ignores boxes with IoU ≤ 0.5 and only considers boxes with IoU > 0.5.
4. Non-Max Supression
Even after applying the IoU technique, there is a possibility that there are more than one boxes for an object. For dealing with that we choose the box with the highest value of confidence score of detection and suppress the Non-max values.
Therefore, the model finally predicts S × S × (C + B ∗ 5).
S = No of grids
C = Number of classes
B= Number of bonding boxes per grid cell.
YOLO Training — Damage detection
For the training of damage detection in cars, we have used the dataset available on Kaggle: MS COCO car damage detection.
This dataset contains 59 train images, 11 validation images, and 8 test images.
As we can see data is too small. For that, we have used a pre-trained YOLO model on the MS COCO dataset which contains 80 categories. We have replaced the final layers and freezed the rest of the model. Then trained for 100 epochs with data augmentation.

Here in the results, we can there are many overlaps, and the probability is also low. Since training data was very low and the pre-trained model was trained on various 80 kinds of class images, therefore, Model was not able to learn much. We can collect more images and manually annotate them to get better accuracy and results.
We can use this damage detection model in Insurance Applications by detecting the damage to the car in an accident which can help users to claim insurance online. And Insurance companies also can save a lot of money since I believe if Machine Learning is not growing business value it is not useful to spend time and money on Machine Learning.
Conclusion
In this blog, we have learned the architecture and working of YOLO algorithms and also seen how YOLO can be used in the industry of Automobiles with Car Damage detection dataset. There are various industries where object detection can be applied such as warehouses, Automated Industries, Healthcare, etc.
As always, drop me a line in the comments if you have any doubts or can be helpful in any way! 😁