

Apache Airflow serves as an open-source platform designed to develop, schedule, and monitor batch-oriented workflows. Leveraging its extensible Python framework, Airflow empowers users to construct workflows that seamlessly integrate with a wide array of technologies. This tutorial guides you through the process of crafting Apache Airflow DAGs to execute Apache Spark jobs.
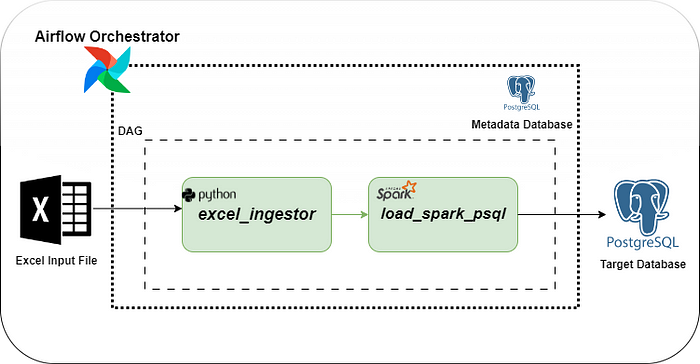
The DAG comprises two tasks:
Task 1: the initial task reads an Excel file from the local environment, transforms it into a CSV file, and saves it to a specified output location in the local folder.
Task 2: The subsequent task reads the CSV file, applies additional transformations, and stores the results in a PostgreSQL table.
Required Steps for the Execution
1. Preparing an environment for Airflow in WSL
2. Prerequisites — WSL should be installed with PostgreSQL and PySpark
Preparing the environment for Airflow
For the current scenario, installing Airflow on WSL which involves the following steps:
Step 1: Make a new directory for Airflow, Update Package Lists and Install dependencies for Airflow.mkdir airflow
sudo apt update
sudo apt install -y python3 python3-pip python3-venv
Step 2: Create a Virtual Environment for Airflowpython3 -m venv airflow-venv
source airflow-venv/bin/activate
Step 3: Install Apache Airflow using ‘pip’pip install apache-airflow
By default, Airflow uses SQLite, which is intended for development purposes only. So for production scenarios, you should consider setting up a database backend to PostgreSQL or MySQL. For the current scenario, we are deploying PostgreSQL as a metadata database. The essential configuration modifications in the /airflow.cfg file within the /airflow directory, created during Airflow installation, governs settings like config files, log directories, and dags_folder where Airflow builds its DAGs.
Open the airflow.cfg by your preferred editor like vim.
- The first thing you have to change is the executor which is a very important variable in airflow.cfg that determines the level of parallelization of running tasks or DAGs. This option accepts the following values:
· SequentialExecutor – which operates locally, handling tasks one at a time.
· LocalExecutor class executes tasks locally in parallel, utilizing the multiprocessing Python library and a queuing technique.
· CeleryExecutor, DaskExecutor, and KubernetesExecutor – For distributed task execution and improved availability these classes are available.
LocalExecutor is the preferred choice in this scenario, as parallel task execution is essential, and high availability is not a priority at this stage.executor = LocalExecutor
2. sql_alchemy_conn — This crucial configuration parameter in airflow.cfg defines the database type for Airflow’s metadata interactions. In this case, PostgreSQL is selected, and the variable is set as follows:sql_alchemy_conn = postgresql+psycopg2://airflow_user:pass@192.168.10.10:5432/airflow_db
Environment setup for PySpark and PostgreSQL for running Airflow
There are some basic setup needed for PostgreSQL and PySpark which includes,
PostgreSQL Environment Setup
You have to create the required user, roles, databases, schema, and tables in PostgreSQL for storing the metadata and the final output from Spark. Go to the Airflow venv and run,sudo apt upgrade
sudo apt install PostgreSQL
sudo service postgresql start
#to get superuser privileges in Postgres
sudo su – postgres
#create a superuser
CREATE USER [user] WITH PASSWORD ‘password’ SUPERUSER;
#command to interact with the PostgreSQL
psql
#for listing the users
\du
#for listing the databases
\l
Now create new DB’s for storing the metadata & spark outputCREATE DATABASE airflow_db;
CREATE DATABASE employee_details;
Now connect to the “etl_db” database and Create a schema and table in the “employee_details” table\c etl_db;
CREATE SCHEMA etl_db;
CREATE TABLE etl_db.employee_details (
Name VARCHAR(255),
Age INTEGER,
City VARCHAR(255),
Salary INTEGER,
Date_of_Birth DATE
);
Now run the below command,airflow standalone
This will initialize the database, create a user, and start all components.
To access the Airflow UI: Visit localhost:8080 in your browser and log in with the admin account details shown in the terminal.
Take another terminal go to airflow venv and run the commands for the required libraries for connecting Airflow with PostgreSQL.pip install psycopg2-binary
pip install apache-airflow-providers-postgres
Spark Environment Setup
go to the Airflow venv and install the Provider Package for Sparkpip install apache-airflow-providers-apache-spark
Install PostgreSQL-42.2.26.jar in airflow venvwget https://repo1.maven.org/maven2/org/postgresql/postgresql/42.2.26/postgresql-42.2.26.jarsudo chmod 777 postgresql-42.2.26.jar#to be used in the code to read the excel files
pip install openpyxl
Now start the Spark Cluster and set the local IP and master IP for Spark by running the below commands,export SPARK_LOCAL_IP=127.0.1.1
export SPARK_MASTER_IP=127.0.1.1
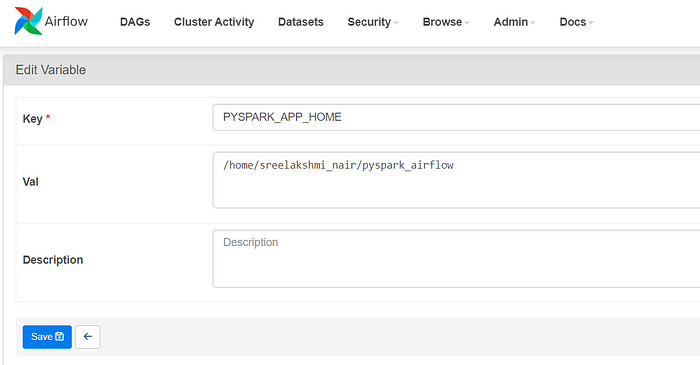
Set Spark app home variable in the Airflow UI — this is very useful to define a global variable in Airflow to be used in any DAG. Useful for getting this variable in code
· Go to Airflow UI’s Admin tab and then Variables,
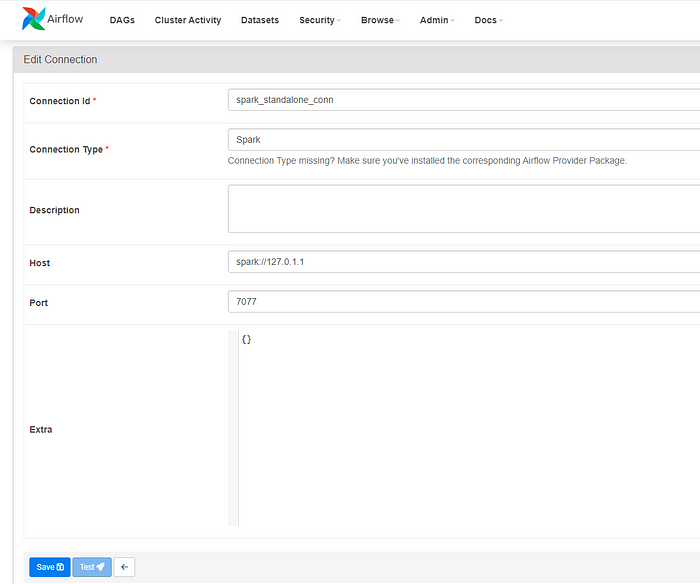
Set up a new connection for Spark in Airflow UI,
· Go to the Admin tab and then “Connections” and add a connection
How to Set Up the DAG Script
The DAG script orchestrates a data pipeline that involves the ingestion of Excel data, transformation using a PySpark application, and loading the transformed data into PostgreSQL.
· DAG Configuration:
The DAG is named ‘excel_spark_airflow_dag’ and is configured with default arguments such as the owner, start date, and email notifications on failure or retry.
· Excel Data Ingestion (PythonOperator):
The ‘excel_data_ingestion task’ is a PythonOperator that executes the transformXL function from the excel_ingestor module. This function reads an Excel file (input_data.xlsx), transforms the data, and saves it as a CSV file (output.csv). The task is set to run on a schedule of every hour (schedule_interval=”0 * * * *”).
· PySpark Application Submission (SparkSubmitOperator):
The load_spark_psql task uses the SparkSubmitOperator to submit a PySpark application (load_spark_psql.py). This application likely performs further transformations or processing on the data and loads it into a PostgreSQL database.
It is configured with parameters such as the Spark connection (spark_standalone_conn), executor cores, memory, driver memory, and packages required for PostgreSQL connectivity.
· Task Dependencies:
The excel_data_ingestion task is set to precede the load_spark_psql task (excel_data_ingestion >> load_spark_psql), indicating that the PySpark application should run after the Excel data has been ingested and transformed.
· Variable Usage:
The PYSPARK_APP_HOME variable is used to define file paths, and it is retrieved using Variable.get(“PYSPARK_APP_HOME”). Ensure this variable is defined in Airflow with the correct path.
· Timezone Configuration:
The DAG specifies the timezone as ‘Asia/Kolkata’ for scheduling purposes.
· Retry and Email Notifications:
The DAG is configured to retry on failure (retries: 0) and send email notifications on failure or retry.
Save the below code as excel_spark_airflow_dag.py in the DAG folder location
Now create the Python scripts “excel_ingestor.py” which contains “tranformXL” function and “load_spark_plsql.py” which contains “transformDB” function. Place these files inside the “pyspark_app_home” variable directory, and using this variable in the code we can access those files.
excel_ingestor.py
load_spark_psql.py
How to Test the Workflow
In Airflow UI’s DAG tab, go to excel_spark_airflow_dag and UnPause the toggle button to start the workflow.
DAG Execution Errors and Resolution
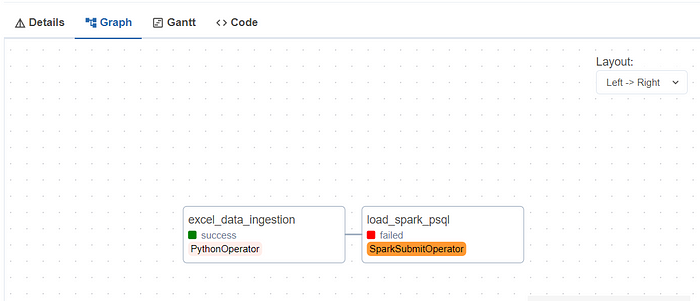
During the execution of the second task, errors were encountered, and these issues can be attributed to the following reasons:
Issue: Spark Cluster Configuration
It appears that the SPARK_LOCAL_IP and SPARK_MASTER_IP environment variables need to be set in the Airflow environment. In our current setup, Airflow attempts to execute the Spark code with the Spark cluster running locally.
Resolution Steps:
1. Navigate to the Spark sbin directory and Set the SPARK_LOCAL_IP and SPARK_MASTER_IPcd /opt/spark/sbin
export SPARK_LOCAL_IP=127.0.1.1
export SPARK_MASTER_IP=127.0.1.1
2. Start the Spark cluster
3. Rerun the DAG.
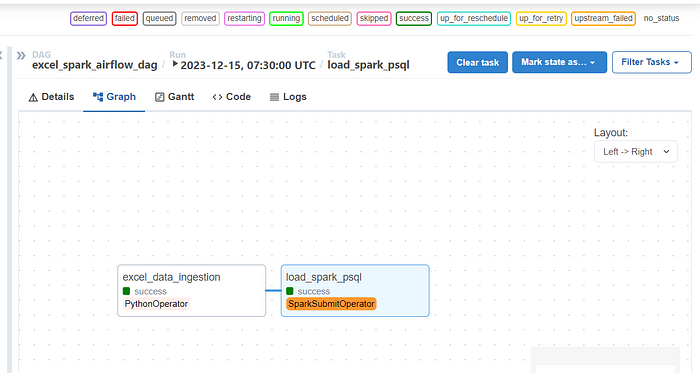
As you can see both the tasks ran successfully and there you have it — your ETL data pipeline in Airflow. We can see the output written in the PostgreSQL table,

References