

After the Generative Adversal Networks (GANs), Variational Auto Encoders (VAE), and Flow-based models, Diffusion Models are the latest research in generative models that can generate diverse high-resolution images. These models also attracted a lot of attention after OpenAI, Google, and Nvidia trained large-scale models. Some examples of pre-trained architecture on Diffusion are DALLE-2, GLIDE, Imagen, etc.
Main Principle behind Diffusion
Diffusion model logic is inspired by non-equilibrium thermodynamics. They define a Markov chain process to add a Gaussian noise slowly to the data and then learn to reverse the diffusion steps to construct the desired data from the noise.
For e.g., A fixes noising process gradually noises the data x₀ to noise xₜ. We learn to reverse it from noise xₜ to data x₀.

You can see the code for adding gaussian noise to the image at this gist.
The idea behind is we add a fixed gaussian noise in a very small amount for series of T steps this is called the Forward pass. Notably, this is unrelated to the forward pass of the neural network.
After the neural network is trained to learn the reverse process, i.e., denoise the image to recover the original data. This is so-called the reverse diffusion process or sampling process of generative models.
Forward process

Now, a fixed Markov Chain is used to add a Gaussian noise with variance βₜ and q is the posterior probability of xₜ given xₜ₋₁. This process can be formulated as below:

Since we are in the multi-dimensional scenario here I is the identity matrix, and it indicates that each dimension has the same standard deviation βₜ. Note that, q(xₜ | xₜ₋₁) is still a normal distribution with mean μₜ

and variance Σₜ = βₜI. Thus, we can now go from x₀, …, xₜ₋₁, xₜ, … x(T) in a tractable way. Mathematically this posterior probability will be defined as

Reverse Diffusion
Now, we need to learn the reverse process i.e, given xₜ learn to predict xₜ₋₁, there posterior probability of q(xₜ | xₜ₋₁). For that, we need to take a parameterized model such as a neural network. Since, we know q(xₜ | xₜ₋₁) will be Gaussian, for small βₜ, we can choose p₀ to be Gaussian and choose mean and variance as parameters.

If we apply reverse diffusion to all the time steps T then the formula will become:

Now, since we need model to learn the mean μₜ and Co-variance Σₜ to predict the Gaussian parameters for each time step.
Model Architecture of Stable Diffusion Model
Since we are talking about the Stable Diffusion model which will be taking text or paragraph of text and trying to create image.
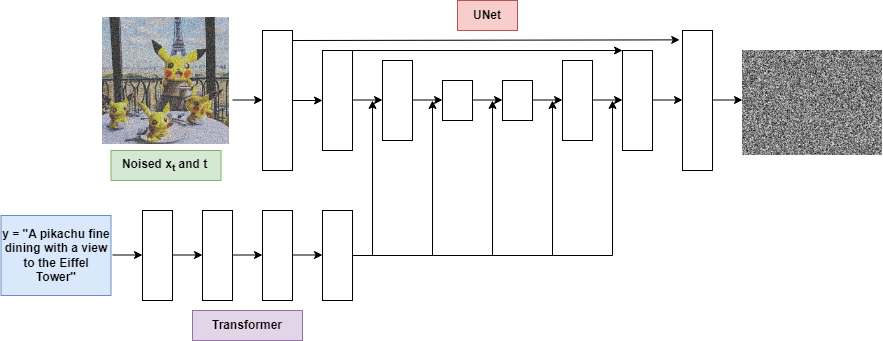
Here, Convolutional UNet architecture is used which is having same output shape as input. UNet uses downsampling and Upsampling layers and various other components such as Residual connections, batch or group normalization layers. Now as we need to pass the description text also, this text is converted into tokens and run Transformer on them. Then attend these transformers into UNet.
Here the model will take noised image xₜ at time step t and try to predict the noise in the image because the variance is set fixed we will output only one value per pixel that means model learns the Mean of the Gaussian distribution of the images this is also called Denoising Score Matching.
Conditional Image Generation: Guided Diffusion
An important step of image generation is to add conditions in the sampling process to manipulate the generated samples. This is also referred to as Guided Diffusion.
There have been methods to guide the distribution using Image/Text embeddings into the diffusion in order to guide the generation. Mathematically we can say, the guidance refers to conditioning a prior distribution p(x) with a condition y as a class label or text embeddings resulting in p(x/y).
For converting a diffusion model to a conditional diffusion model we can add conditioning information y at each diffusion step.

Adding conditioning at each time step may result in excellent samples generation from a text prompt.
In general diffusion models aims to learn ∇logp₀(xₜ|y). Now adding the guidance scalar term ‘s’ we have

Using this guidance, let’s understand the distinction between classifier and classifier-free guidance.
Classifier guidance
Sohl-Dickstein et al. and later Dhariwal and Nichol explained in their paper to use a second model, a classifier fϕ(y∣xₜ,t), to guide the diffusion towards target class y. For achieving that we can train a classifier fϕ(y∣xₜ,t) on the noise image xₜ to predict its class y. Then we can use gradient ∇logp₀(xₜ|y) to guide for diffusion.
Class-free guidance
Here Ho & Salimans proposed a model without a second classifier model. Here author used a single neural network and train a conditional diffusion model together with the unconditional diffusion model. During training, they set y to class 0 randomly, so that model is exposed to both conditional and unconditional setups.
Scaling Up Diffusion Models
The problem with the models we discussed is that these are computationally expensive. And for producing high-quality images, U-Net architecture will be very much expensive. Therefore for producing high-resolution images using diffusion there are two methods: cascade diffusion models and latent diffusion models.
Cascade Diffusion Models
Ho et al. 2021 introduced cascaded models which consist of a pipeline of many sequential diffusion models that generates high-fidelity images. Each model generates a sample with a superior resolution than the previous model. Upsampling layers are used to increase the resolution with the diffusion layer.

Stable Diffusion: Latent Diffusion Models
In Latent Diffusion Models instead of applying diffusion on high-dimensional data, we project the input to a smaller latent space and then apply diffusion
Rombach et al. proposed the idea to use an encoder network to encode the input to a smaller latent representation i.e., zₜ = g(xₜ). The main purpose behind using an encoder is to reduce the computation requirement of the diffusion network by reducing the image to a small latent space. Later, diffusion model (U-Net) is applied to generate new data, and decoder network is used to upsample the image to the original resolution.

Results
Some results of the diffusion model generated from here:
Sample Input 1: “A small cabin on top of a snowy mountain in the style of Disney, artstation.”

Sample Input 2: “Mechanical robot on Indian road”

You can try your own sentences also at https://stablediffusionweb.com/#demo
Summary
Let’s summarize the points, we have learned from diffusion models:
- Diffusion models work on applying fixed Gaussian noise to the original image for T time steps this process is known as diffusion.
- It has two processes Forward and Reverse diffusion. In reverse diffusion, a model or neural network learns to denoise the image.
- We can use an image or text embedding to “guide” the diffusion process.
- Cascade and Latent diffusion are two approaches to scale-up models to high resolution.
- Cascaded diffusion is a sequential diffusion model that uses upscaling layers to create high-resolution images.
- Latent diffusion models apply diffusion in a latent space and are less computationally expensive by using variational autoencoders for upsampling and downsampling.
References
[1] Sohl-Dickstein, Jascha, et al. Deep Unsupervised Learning Using Nonequilibrium Thermodynamics. arXiv:1503.03585, arXiv, 18 Nov. 2015
[2] Ho, Jonathan, et al. Denoising Diffusion Probabilistic Models. arXiv:2006.11239, arXiv, 16 Dec. 2020
[3] Ho, Jonathan, and Tim Salimans. Classifier-Free Diffusion Guidance. 2021. openreview.net
[4] Nichol, Alex, et al. GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models. arXiv:2112.10741, arXiv, 8 Mar. 2022
[5] Rombach, Robin, et al. High-Resolution Image Synthesis with Latent Diffusion Models. arXiv:2112.10752, arXiv, 13 Apr. 2022
[6] Ho, Jonathan, et al. Cascaded Diffusion Models for High Fidelity Image Generation. arXiv:2106.15282, arXiv, 17 Dec. 2021
[7] Weng, Lilian. What Are Diffusion Models? 11 July 2021
[8] Das, Ayan. “An Introduction to Diffusion Probabilistic Models.” Ayan Das, 4 Dec. 2021
[9] Prafulla Dhariwal. “Generative art using diffusion.”
[10] Saharia, Chitwan, et al. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. arXiv:2205.11487, arXiv, 23 May 2022